字符集
一组文本和图形符号,每个符号都映射到一个非负整数
给每个字符分配一个唯一的数值,并建立字符和数值之间的双向映射关系,即字符集、编码表
同一个数值在不同的字符集中对应不同的字符
有了字符集需要定义其编码方式,只有转换为字节才能读取、存储、传输
通常所说的 xxx编码 指的是 用xxx字符集表示数据
计算机中的数据都是二进制形式,xxx编码,就是用二进制对应的xxx字符集中的字符表示数据
Unicode
给每个字符映射一个唯一的整数——代码点(Code Points)或者叫码点、码值
根据Unicode定义,总共有1,114,112个代码点,编号从0x0到0x10FFFF
所有代码点构成一个代码空间(Code Space)
Unicode标准把代码点分成了17个代码平面(Code Plane),编号为**#0到#16。每个代码平面包含65,536(2^16)个代码点(17*65,536=1,114,112)。其中,Plane#0叫做基本多语言平面(Basic Multilingual Plane,BMP**),其余平面叫做补充平面(Supplementary Planes)
BMP 码值范围 0-65535(0-FFFF),2^16,正好可以用2个字节表示
是一种编码标准(字符集),而非编码实现
编码(实现):数据从一种形式或格式转换为另一种形式的过程
表示方式
U+[十六进制码值],例如 U+6B63CJK 中日韩统一表意文字,范围 4E00-9FFF
Emoji
Unicode 只规定了 Emoji 的意义,没有规定具体形态,因此同样含义的Emoji 在不同的平台形状不同
Emoji 码值大都超过 FFFF,在UTF-8编码实现下需要4个字节
常见编码方式(实现)
UTF-8、UTF-16、UTF-32 等及 GB18030
Unicode Transformation Format–UTF,Unicode 转换形式
ucs-2 是 UTF-16 的前身,不完全支持 unicode
ASCII
American Standard Code for Information Interchange,美国信息交换标准代码
美国信息交换标准委员会制定的 7 位二进制码,共有 128 种字符,其中包括 32 个通用控制字符、10 个十进制数码、52 个英文大写与小写字母、34 个专用符号(如$、%、七=等)。除了 32 个控制字符不能打印外,其余 96 个字符全部可以打印
对应 Unicode 的前128个字符,128个码值
书写上可用两位十六进制数表示
ASCII 0~31
不可显示也不可打印
为控制字符(前32个)
ASCII 32
不可显示,可打印
为空格
ASCII 33~126
可打印字符
26个基本拉丁字母、阿拉伯数字和英式标点符号
只能用于显示现代美国英语
7位字符集
只占用了一个字节的后面7位,最前面的一位统一规定为
0比如空格
SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)
ISO-8859-1
又称 Latin-1
收录了256个字符,256个码值,对应 Unicode 的前256个字符
以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用
8位字符集
GB18030
最新版 GB18030-2005《信息技术中文编码字符集》是我国制订的以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,其中收入汉字70000余个
对GB 2312-1980完全向后兼容,与GBK基本向后兼容,并支持Unicode(GB 13000)的所有码位。有以下特点
- 编码空间庞大,最多可定义161万个字符。
- 采用变长多字节传输编码,每个字可以由1个、2个或4个字节组成。
- 完全支持Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及emoji等字符。
Base64
收录了64个字符,64个码值
索引表 https://en.wikipedia.org/wiki/Base64
加上垫字
=实际有65个字符
基于64个可打印字符将二进制数据编码为文本数据(可打印字符)
不关心原始数据是哪种编码方式,仅针对二进制数据的可视化表示
便于 json 传输,用于在 Http 环境下传递较长的标识信息
大小计算
一个base64字符位1字节
base64字符串长度*(1/4)-x 即原始数据的大小(单位 byte)
x 表示base64字符串中=的个数,有效值 0,1,2
转换方式
将24位(3字节)二进制串转换为32位(4字节—4个base64字符)
必须是24位为一组进行转换,因此如果不是24的倍数,需要用0补齐
2字节,补8个0,转换后用1个垫字
=代替字节,补16个0,转换后用2个垫字
=代替
从左到右处理二进制串
每6位为一组,前面补0,构成8位(1字节)
base64 转码后,有效数据占3/4
计算8位二进制的十进制值,对照base64表找出对应的字符
‘Man’ 经过 Base64编码(用Base64字符集表示数据 ‘Man’)
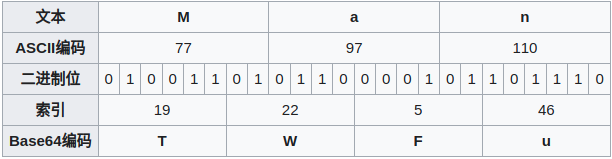
Ma 转换
| 文本 | M | a | - |
|---|---|---|---|
| ASCII编码 | 77 | 97 | - |
| 二进制位 | 010011,01 | 0110,0001 | 00,000000 |
分组补齐 00,010011 00,010110 00,0001,00 00,000000
base64 T W E =
M 转换
| 文本 | M | - | - |
|---|---|---|---|
| ASCII编码 | 77 | - | - |
| 二进制位 | 010011,01 | 0000,0000 | 00,000000 |
分组补齐 00,010011 00,010000 00,000000 00,000000
base64 T = = =
转换表
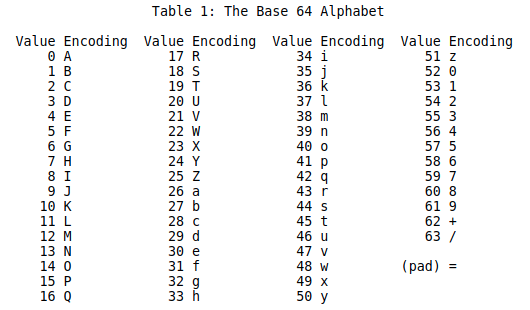
参考
http://www.ruanyifeng.com/blog/2008/06/base64.html
https://en.wikipedia.org/wiki/Base64
Base64URL
标准的Base64编码并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的/和+字符变为形如%XX的形式(Base64 有三个字符+、/和=,在 URL 里面有特殊含义),使的URL变长
Base64URL编码会去掉Base64编码时末尾填充的=,而且把+和/替换成了-和_,URL保持相同的编码形式,且长度不变
转换表
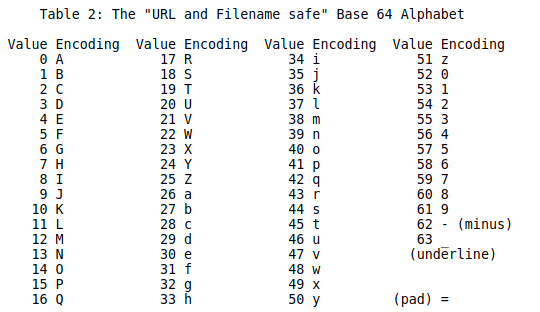
参考:
https://datatracker.ietf.org/doc/html/rfc4648#section-5
GSM-7
是GSM网络中用于SMS (短消息服务)、CB(小区广播)和USSD(非结构化补充服务数据)的字符编码。
但该字符集仅适用于英语和一些西欧语言。中文、韩文或日文等语言必须使用 16 位UCS-2传输字符编码
REGEXP
1 | function isGSMAlphabet(text) { |
其他
big5
中国台湾
编码
两种含义
数据从一种形式转换为另一种形式的过程(通常所说的xxx(字符集)编码,指这种含义)
定义字符对应数值的存储(传输)方式(与字符集对应的编码,指这种含义)
定义字符的序列化和排序规则
数值可以表示为二进制、十进制、十六进制等,但存储方式都是二进制。(计算机用高电平和低电平分别表示1和0)
编码规定一个数值用几个字节去存储,例如十进制2,二进制
编码后也是一个数值,只是将字符集中的码值换一种方式表示,便于存储和传输
注意区分 码值 和 编码值
码值:字符集中的数值
编码值:编码方式中的数值
码值只是抽象概念,只有转换为字节才能读取、存储、传输
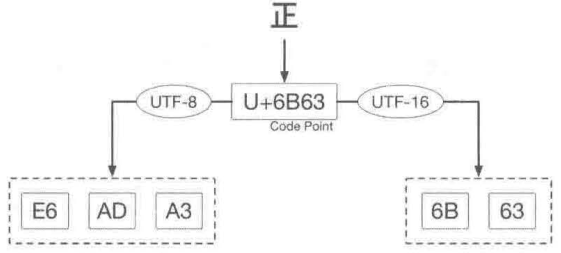
UTF-num
Unicode Transformation Format–UTF,Unicode 转换形式,后面的数字表示一个编码单位(code unit)所占的比特位
UTF-8
编码单元是1字节8比特,即最少占1字节
一种针对Unicode的可变长度字符编码,用一至四个字节对Unicode字符集中的所有有效码点进行编码
转换规则
- 单字节字符,字节的第一位设为0,后面7位为这个符号的 Unicode码(单字节字符与ASCII编码相同)
n字节字符,第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位一律设为10,其余二进制位,从该字符的 Unicode码的最后一个二进制位开始,依次从后向前填入,多出的位补0

大部分中文码值范围 4E00-9FFF,落在 U+0800 到 U+FFFF 区间内,需要占用3字节
示例
| Unicode码值 | 二进制码值 | UTF-8二进制编码值 | UTF-8编码值 |
|---|---|---|---|
| U+0024 | 00000000 00100100 | 0010 0100 | 24 |
| U+4E25 | 01001110 00100101 | 11100100 10111000 10100101 | E4 B8 A5 |
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
UTF-16
编码单元是2字节16比特,即最少占2字节
代理对surrogate pair
1 | // 成对的代理项对 |
第一个代理字符为16位编码,范围为U+D800到U+DFFF,第二个代理字符也是一个16位编码,范围为U+DC00 to U+DFFF
-
计算字符个数
JavaScript 将辅助平面内的字符表示为代理对。通过 String#length 方法为2个字符
1
2'💩'.length
// 2用总字符数减去代理对字符
1
2
3
4const str = '我不是💩'
const strLen = str.length
const surrogatePairs = str.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g) || [];
const len = strLen - surrogatePairs.length;
JS 编码
JavaScript 引擎可以在内部自由使用 UCS-2 或 UTF-16。大多数引擎都使用 UTF-16。这是一个不会影响语言特性的实现细节。
ECMAScript/JavaScript 语言本身根据 UCS-2 而不是 UTF-16 字符