分页查询
处理大量数据时,只返回一部分数据,提高应用的响应速度和用户体验
接口设计
传统分页
处理大量数据
- 通过点击上/下页按钮可实现页面切换
- 通过点击页码可实现页面切换
- 可直接跳转至指定页面
- 多用于 PC 端
页数表示
page+size
一般通过 page size sort search 定义
page
页数
size
每页显示的记录数
sort
排序
search
模糊搜索
like 查询,需要转义
_和%1
value.replace(/(%|_)/g, '\\$1')
返回结果
rows
结果数组
count
总个数
偏移量表示
offset+limit
offset
start
表示从哪里开始
limit
count
表示返回多少数据
返回结果
total
总个数
list
items
数据列表
缺点
数据重复
倒序获取
page = 0,size = 10,获取11-20条
其他客户端插入了一条(第21条)
page = 1,size = 10,获取2-11条
第11条重复
数据缺失
顺序获取
page = 0,size = 10,获1-10条
其他客户端删除了一条(第7条)
page = 1,size = 10,获12-20条
第11条缺失
offset 过大时查询效率低
流式分页
- 通过滚动/上拉/点击等方式加载新一页
- 无页码、无上/下页按钮
- 不可跳转至指定页面
- pc端和移动端均有使用
参考
接口实现
- 数据特点:有一个业务主键,例如order_id、msg_id
- 分页排序按照非业务主键排序,例如按照创建时间来排序
单库
在 created_at 上建立索引,利用SQL提供的 offset/limit 功能
1 | select * from t_order order by created_at offset 200 limit 100; |
分库
参考
高并发大流量的互联网架构,一般通过服务层来访问数据库,随着数据量的增大,数据库需要进行水平切分,分库后将数据分布到不同的数据库实例(甚至物理机器)上
分库 patition key 一般使用业务主键,分库算法一般使用取模算法,即通过业务主键取模来实现分库,保证每个库的数据分布是均匀的。
模数是分库实例个数
分库后,数据分布在多个实例上,数据库层失去了 created_at 的全局视野
全局视野法
每个库都返回 offset+limit 条数据,在服务层对 N*(offset+limit) 条数据进行内存排序,再取 offset 后的 limit 条数据返回
N:分库个数
一般情况,每个数据库都包含一部分目标数据
- 将
order by created_at offset x limit y改写为order by created_at offset 0 limit x+y - 服务层通过改写后的 SQL 从每个分库获取数据
- 服务层对得到的所有数据进行内存排序,构建全局视野,返回指定范围的数据
- 将
优点
- 可以得到全局视野,业务无损,精准返回数据
缺点
- 每个分库要返回 offset+limit 条数据,增大网络传输量(耗网络)
- 服务层需要进行二次排序,增大了服务层的计算量(耗CPU)
- 随着page的增大,offset的增大,每个分库要返回大量的数据,性能会急剧下降
业务折中法
任何脱离业务的架构设计都是耍流氓。在技术难度较大的情况下,业务需求的折衷能够极大的简化技术方案
禁止跳页查询
在数据量很大,翻页数很多的场景,很多产品并不提供“直接跳到指定页面”的功能,而只提供“下一页”的功能,保证数据的检索量和排序量不会随着翻页而增大
第一次只能查询第一页
- 将 order by created_at offset 0 limit 100 改为 order by created_at where created_at >0 limit 100
- 服务层通过改写后的SQL从每个分库获取1页数据
- 服务层对得到的所有数据进行内存排序,构建全局视野,返回指定范围的数据
获取第二页数据
在第一页数据中找到 created_at 最大的值 max_time,作为第二页数据的查询条件
将 order by created_at offset 100 limit 100 改为 order by created_at where created_at >${max_time} limit 100
如果是全局视野法会改为 order by created_at offset 0 limit 200
服务层依然只从每个分库获取1页数据进行内存排序
允许数据精度损失
“全局视野法”能够返回业务无损的精确数据,在查询页数较大,会有性能问题
根据实际业务经验,用户都要查询第100页网页、帖子、邮件的数据了,这一页数据的精准性损失,业务上往往是可以接受的,但此时技术方案的复杂度便大大降低
数据均衡原理:使用 patition key 取模法分库时,在数据量较大,数据分布足够随机的情况下,所有非 patition key 字段,在各个分库上的数据分布情况应该是一致的
例如
- 性别属性,如果db0库上的男性用户占比70%,则db1上男性用户占比也应为70%;
- 年龄属性,如果db0库上18-28岁少女用户比例占比15%,则db1上少女用户比例也应为15%;
利用数据均衡原理,要查询第100页的数据,可平均从每个分库获取,得到的数据集就是第100页的非精准数据
例如:要查询全局100页数据,可将 offset 9900 limit 100 改写为 offset 4950 limit 50,每个分库偏移4950(一半),获取50条数据(半页),得到的数据集可认为是全局100页的非精准数据
优点
- 不需要返回更多的数据,也不需要进行服务内存排序
二次查询法
第一次查询
将总偏移量 offset 按照分库个数 n,均分到每个分库 offset/n,获取指定数量 limit 的数据
将
select*from T order by time offset 1000 limit 5改写为select*from T order by time offset 333 limit 5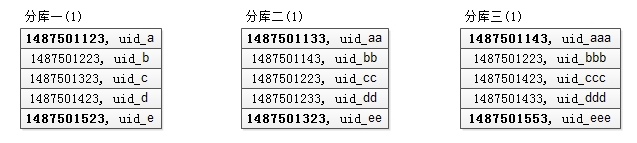
比较各分库返回第一条数据的 created_at,得到最小值 min_time
最小值来自第一个库 min_time = 1487501123
第二次查询
用 min_time 和各分库返回最后一条数据的 created_at 作为查询条件 created_at 的范围,获取数据
将
select*from T order by time offset 333 limit 5分别改写为select*from T order by time where time between min_time and 1487501523select*from T order by time where time between time_min and 1487501323select*from T order by time where time between time_min and 1487501553在每个分库返回数据集中,根据第一次查询第一条记录的索引,找到 min_time 的索引 min_time_i
返回数据如下

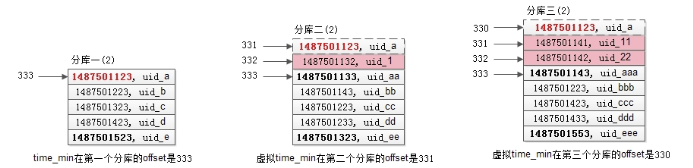
虚拟 min_time 索引如下
i 表示分库编号
将所有分库的 min_time_i 索引加起来就是 min_time 在全局的 offset,即获得了全局视野
第一个库中,min_time在第一个库的offset是333;
在第二个库中,(1487501133, uid_aa)的offset是333(根据第一次查询条件得出的),故虚拟min_time在第二个库的offset是331;
在第三个库中,(1487501143, uid_aaa)的offset是333(根据第一次查询条件得出的),故虚拟min_time在第三个库的offset是330。
因此 min_time在全局的offset是333+331+330=994
根据 min_time 的全局 offset 和第二次查询的结果集,找出指定页的数据
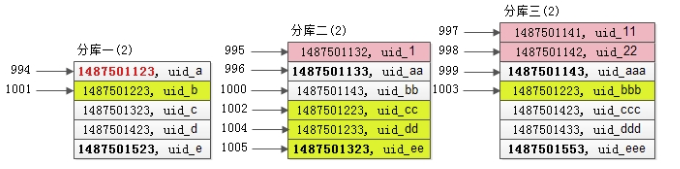
第二次查询在各个分库返回的结果集是有序的,又知道了time_min在全局的offset是994,一路排下来,则全局offset 1000 limit 5的一页记录即上图中黄色的记录
优点
- 满足数据精准度,性能高
- 无需业务折中
缺点
- 需要查询两次