简介
介绍Stable Diffusion 的原理、安装及WebUI和ComfyUI的使用
定义:A latent text-to-image diffusion model
特点
操作复杂,可控制性较高
单次生成的质量较MJ差
每次生成图片的质量是随机的,不是线性递增的
质量高低取决于模型是否用过与提示词相关的图像来训练
质量:指图像的整体效果,包括分辨率、清晰度、颜色准确性、细节保留等因素
画质:指图像中视觉细节的清晰度和精确性,属于图片质量的一部分
应用场景
适合基于原图进行局部修改
工作方式:不用太在意提示词,一次生成大量图片,稍后进行挑选
工作原理
工作流程
可以分为两个主要阶段:
- 添加噪声阶段(前向扩散过程):从清晰的图像开始,模型逐步向图像中添加噪声,直到图像变成纯噪声。这一过程用于训练模型学习如何生成噪声分布。
- 去除噪声阶段(反向扩散过程):从纯噪声开始,模型逐步去除噪声,最终生成逼真的图像。这个过程是模型生成图像的核心。

编码器
文本编码器
- 作用: 将输入的文本提示转换为适合模型使用的特征向量。这个特征向量表示了文本的语义信息,并将其作为条件输入到扩散模型中,指导图像生成过程。
图像编码器
- 作用: 用于将图像输入编码成特征表示。这些特征表示可以与文本编码结合,用于指导特定风格或特征的图像生成
解码器
- 作用: 将隐藏的特征表示转换为最终的输出图像
部署
整合包:包括stable diffusion、ui(webui or comfyui)、模型、插件,知名的有:B站-秋葉aaaki
在线
适合已经知道目标图像风格的场景,直接选择模型去画
云服务器部署
适合大量生成图片
AutoDL部署
步骤
进入 AutoDL 主页
进入主页上的算法社区
选择镜像
WebUI: https://www.codewithgpu.com/i/AUTOMATIC1111/stable-diffusion-webui/tzwm_sd_webui_A1111
ComfyUI: https://www.codewithgpu.com/i/comfyanonymous/ComfyUI/tzwm_ComfyUI
点击右侧:AutoDL创建实例
选择计费方式、地区、GPU型号等
点击立即创建
需实名认证并充钱
创建成功后,点击快捷工具下面的 JupyterLab,进入服务器页面,点击重启,开始部署
部署成功后,点击快捷工具下面的自定义服务,下载隧道工具,安装启动后,填上指令、密码,点击代理,访问下面的本地路径即可
不使用时记得及时关机,否则继续扣费
本地部署
https://github.com/AUTOMATIC1111/stable-diffusion-webui
以下配置生成图片速度 10-20秒
win10 专业版
显卡 4060TI
显存 >=8GB
内存 16GB
硬盘 >=150GB
如何使用
通过WebUI和ComfyUI和SD交互
WebUI
基于网页的用户界面,操作简单,适合调试各种模型、参数
文生图步骤
选择对应的模型
添加提示词
添加参数
生成
设置项
可将当前页面中,下面的所有配置保存为预设样式

模型选择
- 一般添加一个 anything-v5-PrtRE 模型,可以生成任何常见事物的图片
- 画人物就选择用人物训练的模型,且人物风格也取决于训练模型的图片
- 加载模型的过程中,不要生成图片,会报错
外挂VAE模型
在输出图像之前加一层滤镜
- 一般用 Automatic(模型通常已内置)
提示词
公式:主题+背景+个性(特别是画面质量)
使用英文,多个提示词之间使用逗号分隔,是否有空格和换行不影响
对句子识别不好,通常拆分成词
正向提示词
描述想要生成的图片
反向提示词
词通常有固定的几个
1 | ((nsfw)), (worst quality:2), Low quality, EasyNegative |
质量提示词
需要强调画面质量,因为训练模型的图片质量参差不齐
- 正向:masterpiece, best quality, ultra-detailed
- 反向:nsfw, worst quality, Low quality, EasyNegative, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
画风、材质等更多依赖于模型,提示词只是辅助
模型用什么画风、材质的图片训练的,生成的图片就是什么画风、材质的
权重
表示正向或反向的程度
表示方式
权重值表示,格式
提示词:数值小括号表示,格式
(提示词),一层括号表示乘以1.1倍,微调增加权重,可添加多个中括号表示,格式
[提示词],一层括号表示乘以0.9倍,微调降低权重,可添加多个
取值范围
默认是1,大于1增加权重,小于1降低权重
安全范围是 0.1-2
渐变语法,15步以前是白色,15步以后是黄色
1
a girl ,long hair[white:yellow:15]
生成参数
采样方法 sampler
将最终的潜变量向量转换为图像
使用带+的改进过的算法生成图片的质量好
迭代步数 step
步数越多越耗时
一般设置成 20-40 : 低于20较难出现高质量画面,高于40提升较小且时间更长,低于10不可用
高分辨率修复
分辨率
一般最大设置512*512,再由高分辨率修复功能放大,或生成后再进行后期处理
过大的分辨率会产生多个主体和手脚错误
因为训练模型的垫图比较小,而需要生成的图片太大,模型认为可能需要多个人
宽度
高度
总批次数
总共运行多少次
单批次数
运行一次生成图片的数量,数值不要太大,容易占满显存,一般设置1-2
页面右下角会显示本次运行过程占用的显存大小
提示词引导系数
提示词对画面结果的影响,一般为5-10
随机数种子
默认是-1,如果要生成一模一样的图片,需要保持随机数种子一致
ComfyUI
一种模块化的、节点式的用户界面,操作复杂,适合定制工作流
常用节点
Checkpoint 加载器
作用
- 选择模型
CLIP 文本编辑器
本质是一个模型,将文字映射为潜空间下的图像
作用:
- 输入正向、反向提示词
K采样器
作用:
- 连接模型、提示词、latent设定
- 设置生成参数
Latent
作用
- 设定潜空间的图像参数
VAE解码
作用
- 将压缩后的潜在空间的图像特征还原成原始图片
预览图像
保存图像
图像缩放
图像按系数缩放
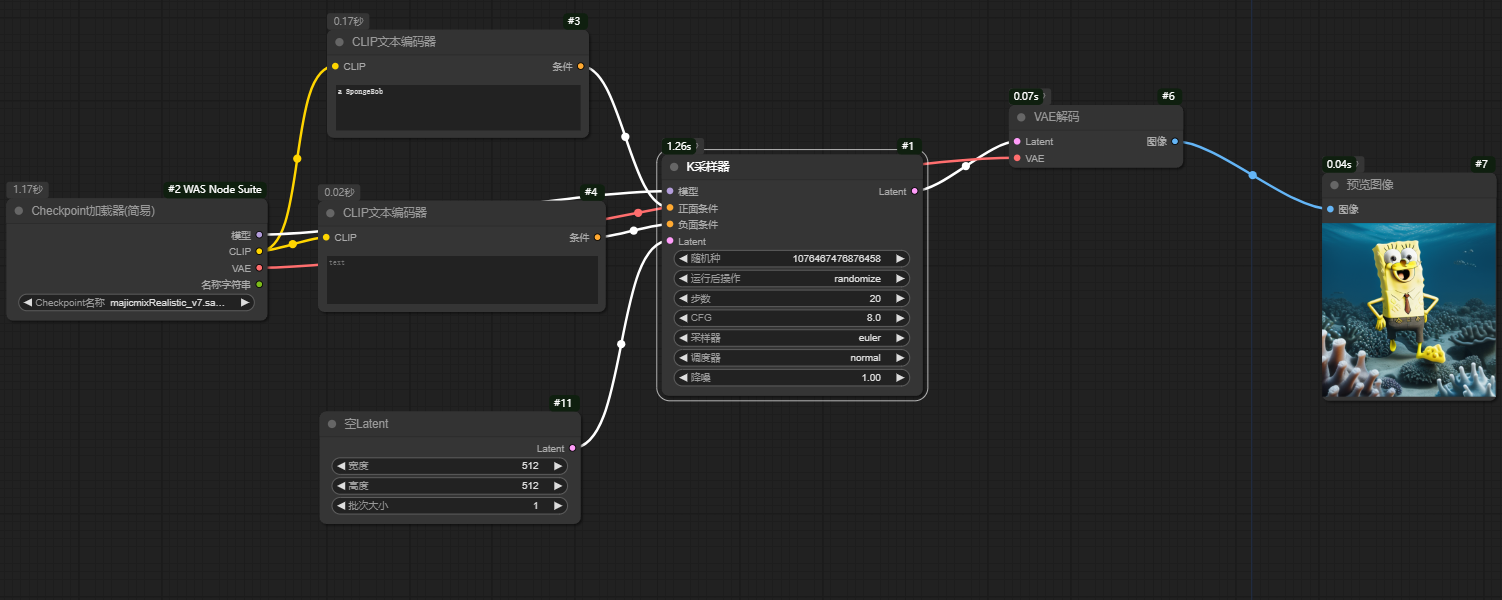
文生图
步骤
- 新建
Checkpoint 加载器和K采样器,以K采样器为中心,前后扩展
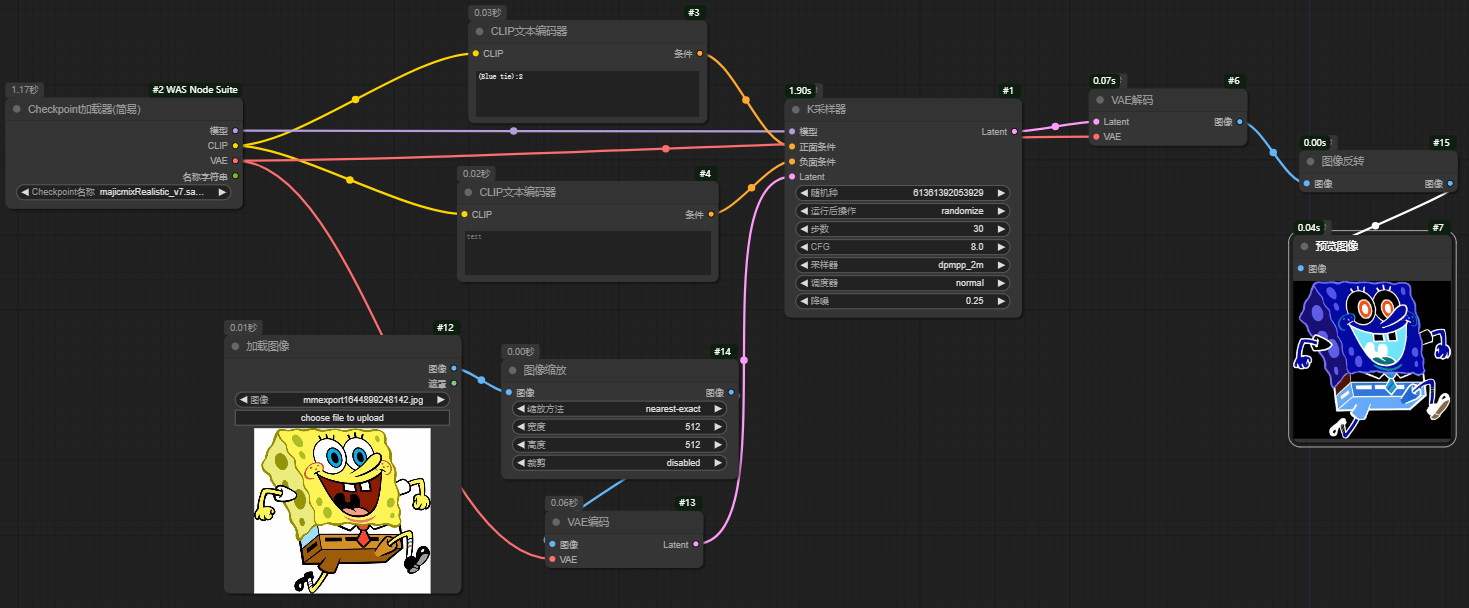
图生图
- 图像需要经过VAE编码器才能与潜空间的采样器连接
- 调整“降噪”来设置重绘比例,1为完全重绘
- 空Latent不能控制图生图, 需要在加载图像后,使用“图像缩放”或 “图像按系数缩放” 来控制,放在“加载图像”和“VAE”编码之间
使用别人的工作流
步骤
加载 json文件
如果节点是红色的,管理器,安装缺失的节点,安装,重启
工作流截图,先按照截图跑一遍,再单个拆解每个节点的原理
参考工作流
官方 https://comfyanonymous.github.io/ComfyUI_examples/