设计表
设计数据库表结构是实现业务逻辑的基础,需要考虑实体之间的关系、属性和索引等
表名
- 采用26个英文字母(区分大小写)和0-9的自然数和下划线组成
- 用单数形式表示
字段名
- 下划线
- 前缀
- 多个表都存在的字段,可以加前缀
- 外键加前缀
- 通用字段不需要加,例如 created_at,
冗余字段
存在外键的情况下,冗余被关联表中的字段
可编辑字段不能冗余
用户昵称
需要保存历史值的字段需要冗余
下订单时商品的历史价格、税率等
中间表
表示两个主体关联关系的字段需要放到中间表中,因为不是两个主体自身的属性。
一对一,将任一主键作为外键可省略中间表
一对多,将一放在多那边可省略中间表,如果不确定以后是否会变为多对多关系,可通过中间表关联
多对多,需要通过中间表来关联
关联关系
一对一
一对多
PG
将“多”的数据放入数组,将一对多变为一对一
MySQL
通过多条记录去体现“多”
设计模式
组织和管理数据库中数据的方法
关联表
用于表示多对多关系,通过一个中间的关联表来实现
特点
- 包含两个表的主键
- 关联查询需要关联多个表
- 中间表的外键添加索引
- 指定过滤条件,限制关联的数据量
父子表
用于表示和存储具有层级关系或树状结构的数据
特点
优点
- 结构简单,易实现
缺点
- 深层结构查询效率低
应用场景
层级结构相对简单,或树的深度不太深的场景
- 组织架构
- 产品类别
- 目录结构
结构
通常用一张表来存储节点和节点之间的层级关系
避免循环引用:一个节点不能是自己的子节点
ID
当前节点ID
Parent ID
当前节点的父节点,如果该字段为 null 或 0/-1,则表示该节点是根节点
其他字段
操作
查询直接子节点
node.pid = curNode.id
查询所有子孙节点
sql递归查询【不推荐,影响性能】
一把查出来,在程序中用递归查询
node.pid = curNode.id
把查询的节点的id作为pid,找pid相等的行,即当前节点的子节点
可以多加一个字段,表示当前记录的root,在一把查的时候减少一点查询量
1
2
3
4
5
6
7
8
9// 查询节点的 id 作为 parentId 调用 buildTree
const buildTree = (nodes, parentId = null) => {
return nodes
.filter(node => node.parent_id === parentId) // 返回的是子节点集合。当返回集合为空时自动结束【结束条件】
.map(node => ({
...node,
children: buildTree(nodes, node.id) // 继续构建子节点
}));
};
查询所有祖先节点
node.id = curNode.pid
优化
用于处理大型或深层次的树结构数据,核心是仅在需要时加载特定部分的数据,而不是一次性加载整个树结构
结合分页和懒加载:当用户尝试展开一个节点时,懒加载该节点的子节点,如果子节点数量众多,应用分页逻辑
分页加载 Pagination
适用于有大量子节点的情况。为子节点设置分页
1 | const loadChildren = async (parentId, pageNumber, pageSize) => { |
懒加载 Lazy Loading
仅在用户尝试访问特定节点时才加载该节点的子节点
在树结构中标记可展开的节点
在构建初始树结构时,对于每个节点,如果它有子节点,则标记为“可展开”,但不立即加载子节点。
按需加载子节点
当用户尝试展开节点时,通过一个API请求来加载该节点的子节点
1
2
3const expandNode = async (nodeId) => {
// 根据nodeId从数据库加载子节点
};更新树结构
将加载的子节点添加到树中相应的位置
闭包表 closure table
用于存储和查询树形或层级结构数据
特点
优点
查询效率高,支持高效的树遍历和查询操作
避免递归或迭代遍历,查询效率高
空间换时间支持复杂的层级关系
缺点
占用空间多
需要维护没对祖先和后代的关系
维护成本高
插入或删除节点时,需要更新多条记录
应用场景
复杂的层级结构
非严格树形结构,可以包含多个父节点
适用于需要频繁查询层级关系的场景
读操作远多于写操作的场景
权限管理系统
表示和查询用户的角色继承和权限层级
一个角色可以继承下级角色的权限
一个权限可以包含多项低级权限
可以灵活的添加、移除、修改角色和权限
表设计
- role 表
- permission 表
- role_permission 表
- role_hierarchy 表
- permission_hierarchy 表
查询角色A的所有权限(包括继承的)
1
2
3
4
5
6
7
8
9
10select p.*
from permission p
join role_permission rp on p.id = rp.permission_id
join role_hierarchy rh on rh.descendant_id = rp.role_id and rh.ancestor_id = roleAId;
SELECT p.*
FROM permissions p
JOIN role_permissions rp ON p.id = rp.permission_id
JOIN role_hierarchy rh ON rp.role_id = rh.descendant_id
WHERE rh.ancestor_id = :roleAId;
结构
通常有两张表:一张是实体表(entity table)另一张是闭包表(closure table)
- 实体表通常包含节点的基本信息,如节点ID、名称等。
- 闭包表存储节点间的层级关系
实体表
ID
节点ID
闭包表
祖先节点 ancestor
表示层级关系中的上级节点
后代节点 descendant
表示层级关系中的下级节点
路径长度 depth
表示从祖先节点到后代节点的跳数,直接父子关系,路径长度为1
示例
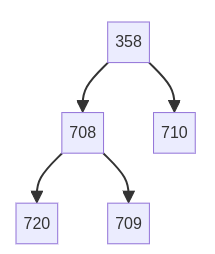
获取358所有后代
| id | ancestor | descendant | depth |
|---|---|---|---|
| 1 | 358 | 358 | 0 |
| 2 | 358 | 708 | 1 |
| 3 | 358 | 710 | 1 |
| 4 | 358 | 709 | 2 |
| 5 | 358 | 720 | 2 |
获取720所有祖先
| id | ancestor | descendant | depth |
|---|---|---|---|
| 1 | 358 | 720 | 2 |
| 2 | 720 | 720 | 0 |
| 3 | 708 | 720 | 1 |
操作
插入节点
插入当前节点,depth=0
插入时是知道当前节点的祖先节点id的
找出当前节点父节点的所有祖先节点
descendant = ancestor_id
插入父节点的所有祖先节点作为间接祖先与当前节点的层级关系,注意 depth 的变化
获取祖先节点
- descendant = find_id
- 如果不包含自己则 depath >0
- 直接祖先节点,depth =1
获取后代节点
- ancestor = find_id
- 如果不包含自己则 depath >0
- 直接后代节点,depth =1
场景
层级关系
单表
每条记录通过父子字段维护层级关系,其他字段记录该层级的数据
| config_id | parent_id | name | value | level |
|---|---|---|---|---|
| 1 | NULL | 学校配置 | NULL | school |
| 2 | 1 | 运动配置 | 配置值 | device |
如果需要构建层级关系,通过sql递归查询影响性能。
要一把查出来在程序中构建,因此可以加一个level字段,表示需要构建层级关系的root节点,便于一把查出该root的所有节点在程序中构建
双表
一张(父子)表用来记录层级关系
| level_id | parent_id | name |
|---|---|---|
| 1 | NULL | 学校配置 |
| 2 | 1 | 运动配置 |
一张表记录每个层级的数据,通过一个层级字段来表示所属层级
| item_id | level_id | key | value | … |
|---|---|---|---|---|
| 1 | 2 | 运动类型 | 篮球 | … |
构建层级关系
双表情况下,较容易构建层级关系。先通过 层级关系表 找出所有层级(数据量不大),再根据层级id去 层级数据表 中查对应层级的数据
便于维护复杂层级关系和大量的层级数据