简介
正则表达式处理的都是字符串,而不是字符
表示形式
- Java、.NET、Python、PHP 中的正则表达式以字符串形式给出
"RegExp" - JavaScript 中的正则表达式以首尾两个斜线形式给出
/RegExp/或正则对象(字符串)形式给出new RegExp(regexpStr)
- Java、.NET、Python、PHP 中的正则表达式以字符串形式给出
子表达式也叫元素指正则表达式中的某个部分
某个元字符或结构(字符组、括号)
正则表达式只能进行纯粹的文本处理,不能解析文本的层次结构,需要配合程序代码
正则表达式两端的
/是分隔符正则表达式的删除操作都是通过将文本替换为空字符串实现的
Javascript不支持递归正则表达式
流派
正则表达式源自 Perl,根据实现(解析引擎)不同分为多个流派
PCRE - Perl Compatible Regular Expression
是一个库,实现了 Perl5。
例如支持 \d \w \s 等简写
参考
Posix - Portable Operating System Interface for uniX
可移植操作系统接口,定义了Unix系统应该支持的功能,其中就包括正则表达式规范。规范包括BRE和ERE
BRE
Basic Regular Expression-基本正则表达式
GNU grep, vi, sed 支持BRE
参考
ERE
Extended Regular Express-扩展正则表达式
GNU egrep, awk 支持ERE
参考
参考
元字符
在正则表达式中有特殊含义的字符
例如
^$[]-.如果需要表示普通字符,通过需要转义,即在元字符前加上反斜杠
\一些特殊结构有特殊的规定,例如字符组中横线在开头
[-09]表示普通字符,在中间表示元字符[0-9]
特殊元字符
点号.
匹配除换行符\n之外的所有字符(包括点号字符)
单行模式下可以匹配换行
“自制”通配字符组[\s\S]或[\d\D]或[\w\W]可以在任何模式下匹配所有字符
量词元字符
quantifier
限定量词之前的元素出现的次数。通用形式为{m,n},下限m默认为0,上限n默认为65536
量词元字符控制前面元素的匹配优先级和次数,匹配优先则,先于表达式之后的元素匹配;忽略优先则,后于表达式之后的元素匹配
匹配优先量词只需要考虑自己限定的元素能否匹配,忽略优先量词必须兼顾它所限定的元素及之后的元素,效率会降低。字符串较长时,两者的速度会有明显差异
"[^"]*"等价(优)于".*?"
[^"]能匹配换行符- 匹配优先量词效率高
匹配优先量词
贪婪量词 greedy quantifier
遇到可以匹配的字符,先尝试匹配,并记录下这个状态(也可以不匹配),以备回溯。如果匹配到字符串结尾,但正则表达式中还有剩余元素未匹配,则回溯,量词尝试忽略部分字符,使忽略的字符可以匹配剩余的元素
| 通用形式量词 | 说明 |
|---|---|
| {n} | 出现n次 |
| {m,n}(逗号后面不能有空格) | 最少出现m次,最多出现n次 |
| {m,} | 至少出现m次 |
| {0,n} | 可以出现,也可以不出现,最多出现n次 |
| 量词简记法 | 等价通用形式 | 说明 |
|---|---|---|
| * | {0,} | 匹配前一个表达式 0次或多次,默认贪婪模式(匹配多次) |
| + | {1,} | 匹配前一个表达式 1次或多次,默认贪婪模式(匹配多次) |
| ? | {0,1} | 匹配前一个表达式 0次或一次,,默认贪婪模式(匹配一次) |
忽略优先量词
懒惰量词 lazy quantifier
遇到可以匹配的字符,先尝试忽略,并记录下这个状态(也可以匹配),以备回溯。优先匹配之后的元素,如果之后的元素匹配失败,则回溯,量词尝试匹配部分字符,使剩余的字符可以匹配之后的元素
在匹配优先量词后面加?
仅适用于不确定长度匹配
| 匹配优先量词 | 忽略优先量词 |
|---|---|
| * | *? |
| + | +? |
| ? | ?? |
| {m,n} | {m,n}? |
| {m,} | {m,}? |
| {0,n} | {0,n}? |
2
3
4
[ 'a', index: 0, input: 'aaaab', groups: undefined ]
> /a+?b/.exec('aaaab')
[ 'aaaab', index: 0, input: 'aaaab', groups: undefined ]
- 先跳过表达式
a+?,匹配表达式b,第一个字符’a’匹配失败,回溯,表达式a+?匹配第一个字符’a’,重复之前的过程,表达式a+?一直匹配到第三个字符’a’。此时再次匹配表达式b,和最后一个字符’b’匹配成功,则正则匹配结束,匹配项为 aaab
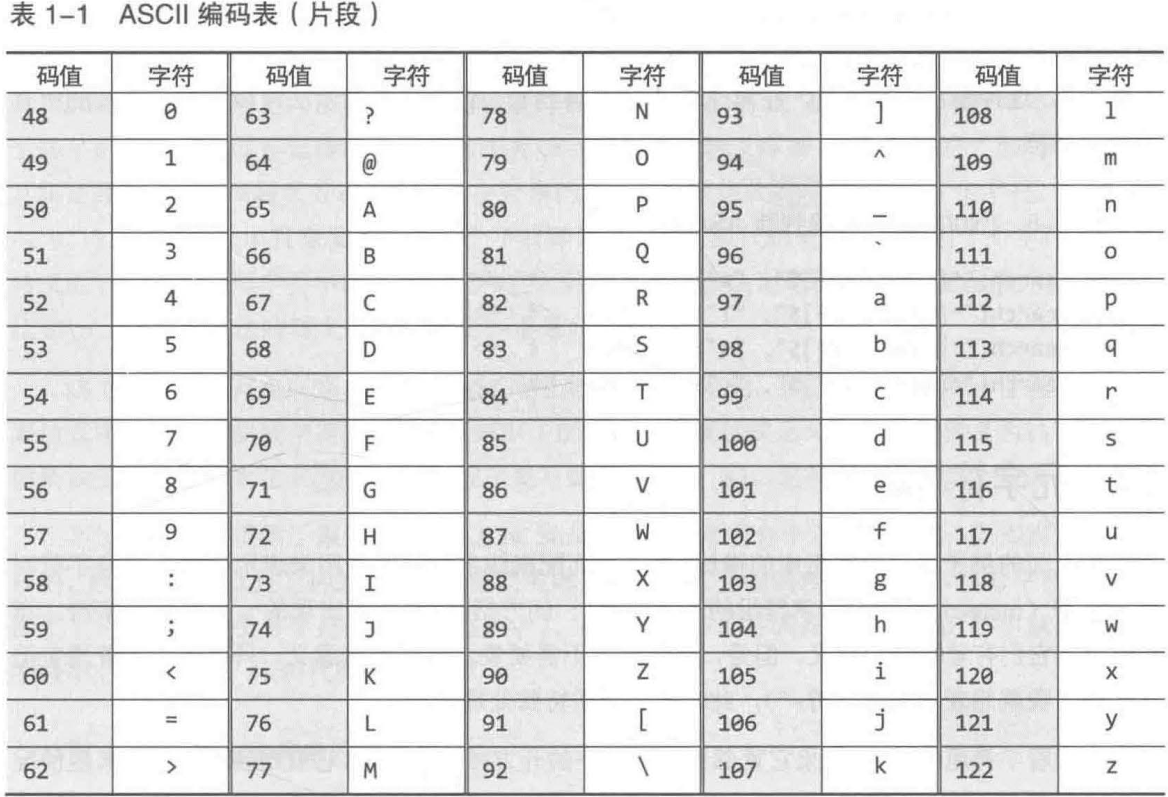
==结构==
可以称为元字符也可以理解为元字符组成的结构,包括字符组、括号
字符组
Character Class
由元字符[ - ]组成
普通字符组
格式
字符组中的闭方括号]会优先与最近的开方括号[匹配,匹配成功则表示字符组,匹配失败则仅表示普通字符]
枚举表示法
在一对方括号之间列出所有可能出现的字符
[xyz]范围表示法
用
[x-y]的形式表示x到y范围内的所有字符一个范围一般用来表示同一类字符,可同时并列多个范围
[0-9a-zA-Z]匹配数字、大小写字母
[0-9a-fA-F]匹配十六进制字符
本质是根据字符在ASCII编码表中的码值来确定的,码值小的在前,码值大的在后
描述
- 表示在当前位置,匹配一个列出的字符
- 字符组中字符排列的顺序和重复字符不影响字符组的功能
排除字符组
格式
在普通字符组的开方括号后紧跟一个脱字符^即[^xxx]
描述
- 表示在当前位置,匹配一个没有列出的字符
简记法
shorthands
| 字符组 | 简记法 | 描述 |
|---|---|---|
| [0-9] | \d | 数字字符 |
| [^0-9] | \D | 非数字字符 |
| [0-9a-zA-Z_] | \w | 单词字符(字母数字下划线) |
| [^A-Za-z0-9_] | \W | 非单词字符 |
| [ \t\r\n\v\f] (第一个字符是空格) | \s | 空白字符 |
| [^ \t\r\n\v\f] (第二个字符是空格) | \S | 非空白字符 |
空白字符包括 空格符、制表符\t、回车符\r、换行符\n 等不方便显示的字符(显示或打印出来都是空白)
因此匹配”空白”时,不一定是空格符,需要用
\s去匹配利用字符组的互补特性
[\s\S][\w\W][\d\D]匹配所有(任意)字符。默认情况.不能匹配换行符以上简记法的匹配规则针对 ASCII编码,即 ASCII规则。如果支持 Unicode 字符,则数字字符、单词字符、空白字符的范围将扩大,即 Unicode规则
可以单独出现也可以用在字符组中,如果出现在字符组中不要出现单独的横线-
[^0-9][^\d][\D]都表示非数字不要出现单独的横线,例如
[\d-a]会让人迷惑
括号
由元字符( | )组成
括号的三个作用:分组、多选结构、分组引用同时存在
单纯的分组可以视为只包含一个分支的多选结构,在匹配时视为一个整体,且正则引擎会保存匹配的文本,以供引用
分组
把若干连续的字符或子表达式用括号括起来,格式(xxx)
在匹配时,括号内的表达式作为一个整体(单个元素)
应用场景
有些元素是不一定出现的,但它们之间却是有关联的(同时出现),此时就要分为一组
合并两个表达式时,可以将不同的部分视为一组,用量词
?修饰15位身份证号码
[1-9]\d{14}18位身份证号码
[1-9]\d{16}[0-9x]合并
[1-9]\d{14}(\d{2}[0-9x])?
多选结构
在括号内用竖线|分隔开多个子表达式,每个子表达式叫做一个分支,格式(xxx|yyy)。
括号用于规定多选结构的范围,也可以不用括号,只出现竖线
|,此时将整个表达式视为一个多选结构
ab|cd等价于(ab|cd)
在匹配时,括号内的所有分支作为一个整体,只要其中一个分支匹配成功,则多选结构匹配成功。如果所有分支都匹配失败,则多选结构匹配失败
修饰分支的量词和修饰括号的量词有时会同时出现,有时可以省略修饰分支的量词
2
3
4
// 最后的 [^'"] 没有添加量词
// 1. 因为外层有`+`修饰,保证子表达式可以匹配多个字符
// 2. (xxx*)+ 的回溯次数会呈指数增长
多选结构分支的排列顺序会影响匹配结果,一般优先选择最左侧的分支。应避免多选结构中存在多个分支重复匹配的情况,这样会增加回溯次数,影响匹配效率
湖南|湖南省匹配 “湖南省”的结果为 “湖南”
湖南省|湖南匹配 “湖南省”的结果为 “湖南省”正则表达式
([0-9]|\w)中存在重复匹配的情况,[0-9]和\w都可以匹配数字字符属于传统型 NFA 引擎——优先选择左侧的分支
多选结构vs字符组
字符组写法简洁,执行效率高
[abc]比[a|b|c]简洁且执行效率高字符组的每个”分支”长度相同,且只能是单个字符
多选结构的每个分支没有长度限制,且可以是复杂的表达式
排除字符组可以表示”无法由某几个字符匹配的字符”,而多选结构不能表示”无法由某几个表达式匹配的字符串”
[^abc]表示”匹配除 a b c 之外的任意字符”(^a|b|c)不能表示”匹配除 a b c 之外的任意字符串”
应用场景
匹配字符串有多种情况时,每种情况作为一个分支去匹配
IPv4 地址
分组引用
捕获分组
分组后,在匹配时正则引擎会保存每个分组匹配的文本,通过分组编号引用(引用的是匹配的文本而非表达式)。这种分组也叫捕获分组
只要出现括号,正则引擎在匹配时就会保存每个分组匹配的文本,会降低正则匹配的性能
捕获分组的个数是不能动态变化的,在匹配前就要确定,表达式中有几个捕获分组,匹配结果中就对应多少个文本。如果要捕获数目不定的文本,需要通过多次匹配完成
2
3
4
5
6
7
8
9
10
11
[ 'aa.', 'bb.', 'cc.', 'dd' ]
> /(\w+\.?)+/.exec('aa.bb.cc.dd'); # 表达式 /\w+\.?/ 会匹配1至多次,只保存最后一次匹配的文本
[
'aa.bb.cc.dd',
'dd',
index: 0,
input: 'aa.bb.cc.dd',
groups: undefined
]
分组编号规则
- 从左向右,从1开始,为开括号
(编号。 - 默认编号为0的分组对应整个表达式匹配的文本
- 只考虑捕获分组的括号,不考虑其他作用的括号(例如:非捕获分组、环视结构的括号)
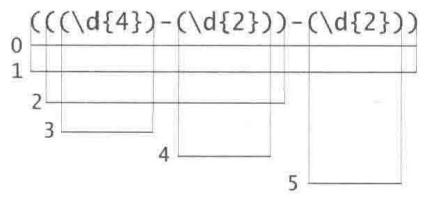
量词修饰分组,表示括号中的子表达式重复出现,且编号都是1。每次重复出现就要更新匹配结果,最终匹配的文本仅仅是最后一次匹配的结果
2
3
4
5
6
7
8
9
10
11
12
[
'2021-06-17',
'1', # \d 重复匹配4次,捕获的结果依次是 2 0 2 1,只保存最后一次匹配的结果 '1'
'06',
'17',
index: 0,
input: '2021-06-17',
groups: undefined
]
> /(\d){4}-(\d{2})-(\d{2})/.exec('2021-06-17')[1];
'1'
数据替换
在替换文本中引用捕获分组匹配的文本,形式$num,num表示捕获分组的编号
匹配结束进行数据替换时引用
Javascript 中没有 $0
1 | > '2020-11-12'.replace(/(\d{4})-(\d{2})-(\d{2})/,'$2-$3-$1') |
反向引用
在正则表达式内部引用之前(左侧)捕获分组匹配的文本,形式\num,num表示捕获分组的编号
匹配过程中引用
只引用文本,本身不规定文本的特征
断言
反向引用时,之前捕获分组中的断言都会被忽略。
如果反向引用的捕获分组涉及断言,则反向引用时只引用文本,对文本的约束(断言)都会丢失
1 | > /(\bcat\b)\s+\1/.exec('cat cate'); |
二义性
num 如果是两位数,则存在二义性,例如 \10 是引用编号为10的分组还是编号为1的分组和字符0
JavaScript规则
- 不管是否存在对应的捕获分组,都会引用对应的分组匹配的文本。如果没有对应的分组,则正则表达式匹配失败
- 如果想表达引用编号为1的分组和字符0,需使用括号
(?:\1)0或\1(?:0)
1 | > /(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)\10/.exec('01234567899'); # 存在对应的捕获分组 |
命名分组
named grouping
使用字符串(名称)作为引用标识的捕获分组,形式(?<name>regexp),name 为捕获分组的引用标识
为保证向后兼容,命名分组同时也具有数字编号,也可以通过数字编号来引用
1 | > /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/.exec('2020-11-12') |
引用格式
反向引用 \k<name>
1 | > /(?<char>[a-z])\k<char>/.test('aa') |
替换文本引用 $<name>
1 | > '2020-11-12'.replace(/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/,'$<month>/$<day>/$<year>'); |
URL Rewrite
Web 服务器具备的功能,用来进行网址转发,隔离外部接口和内部实现,方便修改
外部访问 http://www.example.com/blog/2006/12
内部转发 http://www.example.com/blog/posts.php?year=2006&month=12
通过转发规则来实现,每条转发规则对应一类URL,通过正则表达式提取外部访问URL中的信息,重组为内部转发URL再转发
非捕获分组
只匹配不捕获文本的分组,形式(?:xxx)
分组编号时只考虑捕获分组,忽略非捕获分组
1 | > /(\d{4})-(\d{2})-(\d{2})/.exec('2020-11-12')[1] |
==断言==
匹配一个位置,它的左侧或右侧满足指定的条件,这种结构称为断言,常见的断言有三类:单词边界、行起始/结束位置、环视。
匹配位置的元字符又叫锚点(anchor)
字符前后都是位置
单词边界\b
匹配位置:一边是单词字符,一边不是单词字符(可以出现非单词字符或没有任何字符)
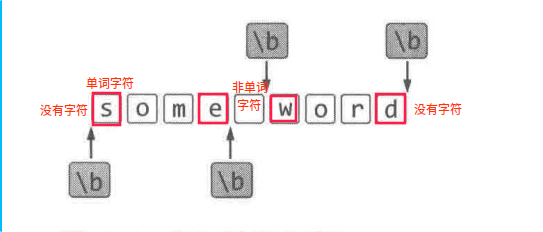
单词字符即 \w 能匹配的字符
1 | > 'tomorrow i will wear in brown standing in row 10'.replace(/row/g,'line'); |
行起始^结束$位置
单行模式
^ 匹配字符串起始位置

$ 匹配字符串结束位置(如果最后是行终止符则匹配行终止符之前的位置,否则匹配最后一个字符之后的位置)

多行模式
| 系统 | 行终止符 |
|---|---|
| Unix/Linux | \n |
| Windows | \r\n |
| Mac OS | \n |
\r叫 回车符,让打印头回到初始位置
\n叫 换行符,让打印纸向上移动一行
^ 匹配整个字符串起始位置以及内部行起始(行终止符之后的)位置
!!! JavaScript 中
^只匹配整个字符串起始位置

$ 匹配整个字符串结束位置以及内部行结束(行终止符之前的)位置
整个字符串结束位置:如果最后是行终止符则匹配行终止符之前的位置,否则匹配最后一个字符之后的位置
!!! JavaScript 中
$只匹配最后一个字符(包括行终止符)之后的位置
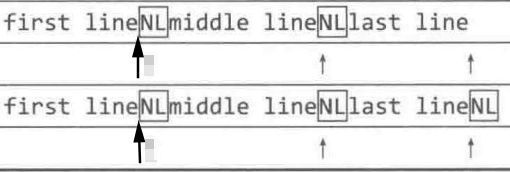
应用场景
整体匹配
单行模式下,^ 和$组合可以判断整个字符串是否能由表达式匹配
数据替换
在起始/结束位置进行数据替换,位置本身不会被替换,只会将数据添加到对应位置
环视
匹配一个位置,它的左侧或右侧需要满足约束条件
格式
共有4种格式
| 类别 | 格式 | 判断方向 | 环视结构的匹配成功 |
|---|---|---|---|
| 肯定顺序环视(positive-lookahead) | (?=regexp) | 右侧 | 子表达式匹配成功 |
| 否定顺序环视(negative-lookahead) | (?!regexp) | 右侧 | 子表达式匹配失败 |
| 肯定逆序环视(positive-lookbehind) | (?<=regexp) | 左侧 | 子表达式匹配成功 |
| 否定逆序环视(negative-lookbehind) | (?<!regexp) | 左侧 | 子表达式匹配失败 |
判断方向:顺序–>右侧(之后),逆序–>左侧(之前)
约束条件:肯定–>子表达式匹配成功,否定–>子表达式匹配失败
肯定环视匹配成功,字符串中判断方向侧必须有字符匹配子表达式
否定环视匹配成功,字符串中判断方向侧有字符但是不匹配子表达式或没有任何字符(字符串起始/结束位置)
因此尽量使用否定环视,例如”不是数字字符” 用
(?!\d)不用(?=\D)将环视结构视为一个锚点,看它判断的方向以及指定的条件。环视结构的匹配结果更看重其对判断方向侧字符的约束条件
只匹配位置,环视结构中的子表达式只作为条件判断,不用于匹配字符。匹配过程不”消耗”字符,不改变游标位置
JavaScript 对子表达式无任何限制
4种格式的环视结构匹配字符串 12345 的位置
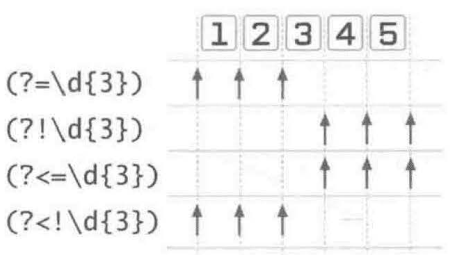
匹配原则
找到一个开始匹配的位置——在它的右侧,最左侧的文本能由环视结构中的子表达式匹配,其他元素也可以成功匹配
从字符串开头开始找「这个位置」
正则引擎从「这个位置」开始匹配(开始匹配的位置并非环视结构匹配的位置)
全局正则匹配的起始位置
逆序环视,全局匹配的起始位置由逆序环视匹配的位置决定
顺序环视,全局匹配的起始位置即「这个位置」
1
2> /(?<=(ab+))cd/.exec('abcabbcd');
[ 'cd', 'abb', index: 6, input: 'abcabbcd', groups: undefined ]正则引擎从第3个字符 ‘c’ 后面的位置开始匹配。「这个位置」右侧最左侧的文本 ‘abb’ 可以由环视子表达式
(ab+)匹配如果从字符串开始位置匹配,右侧最左侧文本 ‘ab’ 可以由环视子表达式匹配,但是全局正则
cd无法匹配文本 ‘cabbcd’,所以,正则引擎继续向右寻找「这个位置」逆序环视匹配的位置为第6个字符 ‘b’ 后面的位置。全局正则从该位置开始匹配,文本 ‘cd’ 由全局正则
cd匹配
1
2> /(?=(ab+))cd/.exec('abcabbcd');
null正则引擎从第1个字符 ‘a’ 前面的位置开始匹配。这个位置右侧最左侧的文本 ‘ab’ 可以由环视子表达式
(ab+)匹配顺序环视匹配的位置也是字符 ‘a’ 前面的位置。全局正则从该位置开始匹配,全局正则
cd无法匹配文本 ‘abcabbcd’正则引擎继续向右寻找「这个位置」,直到第3个字符 ‘c’ 后面,这个位置右侧最左侧的文本 ‘abb’ 可以由环视子表达式
(ab+)匹配顺序环视匹配的位置也是第3个字符 ‘c’ 后面。全局正则从该位置开始匹配,全局正则
cd无法匹配文本 ‘abbcd’正则引擎继续向右寻找「这个位置」,直到字符串末尾也没有这个位置,至此,正则表达式匹配失败
环视结构子表达式匹配长度
逆序环视,属于懒惰匹配,确定「这个位置」后,从左往右,匹配逆序环视子表达式,如果有量词则采用忽略优先
顺序环视,属于贪婪匹配
1 | > /(?<=(\d+))(\w+)(\1)/.exec('123a12') |
捕获分组
环视结构的括号不影响分组编号,但是环视结构中的子表达式可以使用捕获分组,影响整体分组编号。
- 环视结构子表达式不作为整体表达式的一部分(不是全局匹配的一部分)
- 环视结构中的捕获分组,一旦匹配就跳出环视结构,丢失状态,不能回溯
1 | > /(?<=(\d+))(\w+)(\1)/.exec('123a12') # 左侧为数字字符,从字符1开始匹配 |
组合方式
环视结构匹配的是位置,不”消耗”字符,不改变游标位置,多个环视可以组合在一起,在同一个位置进行多重条件判断
嵌套环视(与)
两个环视具有且的关系,其中一个匹配失败,则整体匹配失败。形式(?[]regexp(?[]regexp))
外层环视匹配的位置实际上有两个约束条件,自己的和内层环视的;内层环视匹配的位置只有一个约束条件
两个环视匹配不同的位置,内层环视匹配的位置依赖外层环视子表达式匹配的结果
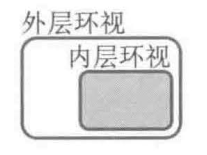
1 | > /(?=\d+(?<=8))/.exec('01234567'); # 内层嵌套匹配失败 |
并列环视(与)
两个环视具有且 的关系,其中一个匹配失败,则整体匹配失败。形式(?[]regexp)(?[]regexp)
两个环视的先后顺序无所谓,匹配相同的位置,同一个位置有多个约束条件
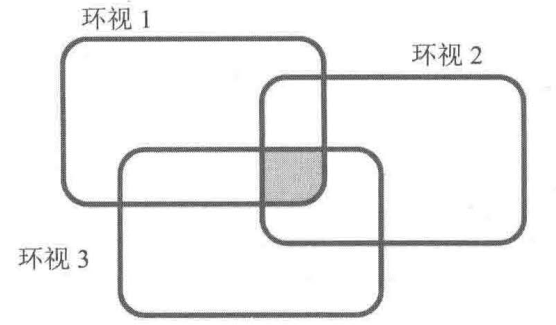
1 | > /^(?=\d+)(?!1)/.test('23') |
多选环视(或)
两个环视具有或的关系,只要其中一个匹配成功,则整体匹配成功。形式((?[]regexp)|(?[]regexp))
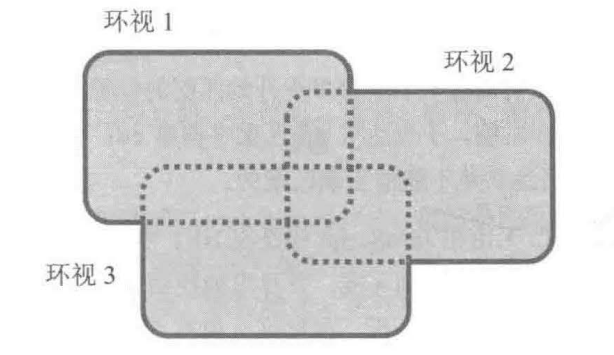
1 | # 查找一个起始位置,之后要么不是数字字符,要么是一个数字字符和一个非数字字符 |
应用场景
匹配位置数据替换
格式化数字字符串
需求:将12345格式化为12,345
规则:
把逗号添加到这样的位置
- 「位置」右侧数字字符串的长度是3的倍数,且「这些数字字符串」的右侧不能再有数字字符
- 「位置」左侧是数字字符
正则表达式 (?<=\d)(?=(\d{3})+(?!\d))
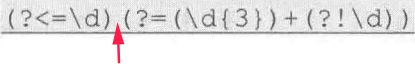
3倍的表示方法
(\d{3})+并列环视,同一个位置左右两侧都需满足约束条件
添加约束以配合其他元素的匹配
关键是准确匹配其他元素,不限制字符串的匹配范围
中英文混排去除空格
需求:将” 中 英文混排,some english word,有多余的空 白字符 “,去除多余空格
规则:
去除中文之间的空格,英文之间的空格不变
- 「位置」左侧不能出现英文字母右侧为空格或左侧为空格右侧不能出现英文字母
正则表达式(?<![a-zA-Z]\s+(?![a-zA-Z]))
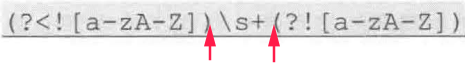
提取有长度特征的数据
匹配邮政编码
规则:
由6位数构成的字符串
正则
\d{6}左右量词都不能是数字
环视
(?<!\d)(?!\d)
正则表达式 (?<!\d)\d{6}(?!\d)
添加约束以限制其他元素的匹配范围
需要限制目标元素匹配字符串的范围
- 考虑 环视约束条件的匹配范围、匹配字符串的长度 和 目标元素的匹配范围、匹配字符串的长度 之间的关系
- 环视可以否定也可以肯定
E-mail地址
规则:
主机名以点号分隔为多个域名段
正则
\.每个域名段可以包含大小写字符、数字、横线,但是横线不能出现在开头,最长为63个字符
正则
((?!-)[-a-zA-Z0-9]){1,63}整个主机名长度最多为255个字符
正则
(?=[-a-zA-Z0-9.]{0,255})只要求该位置右侧可以匹配一个长度在255以内的目标字符串,并不能保证右侧整个字符串长度在255以内。可能右侧有256个目标字符,此时第一个字符一定不是E-mail地址,E-mail地址一定在后面的255个字符中文本中有一个E-email地址,E-mail地址最长255个目标字符,此时有连续的256个目标字符,如果满足E-mail的格式,只能从第二个字符开始识别。如果从第一个字符开始识别,且这个E-mail地址恰好是255个字符,此时最后一个字符与E-mail地址连在一起,就不符合E-mail地址的格式了。
主机名之后可以有其他字符(非大小写字符、数字、横线),有可能是空白字符或在字符串的结尾,没有任何字符
正则
(?![-a-zA-Z0-9.])
正则表达式 (?=[-a-zA-Z0-9.]{0,255}(?![-a-zA-Z0-9.]))(?:(?!-)[-a-zA-Z0-9]{1,63}\.)*(?!-)[-a-zA-Z0-9]{1,63}
1 | > /^(?=[-a-zA-Z0-9.]{0,255}(?![-a-zA-Z0-9.]))(?:(?!-)[-a-zA-Z0-9]{1,63}\.)*(?!-)[-a-zA-Z0-9]{1,63}$/.exec('example.com'); |
环视约束条件的匹配范围 与 目标元素匹配范围 相同。匹配长度大于目标元素
匹配辅音字母
1 | > 'abcdef'.match(/(?=[^aeiou])[a-z]/g) # 一个一个字符的去匹配,依次匹配a、b、c、e后面的位置 |
环视约束条件的匹配范围 是 目标元素匹配范围的 子集。每次匹配时匹配长度相同
其他
1 | > /^(?!([a-zA-Z0-9]{2}))/.exec('e_xample_.com'); |
开头不是 [a-zA-Z0-9] 字符组中的任意两个
例子中,开头为
e_符合约束条件,但是没有与捕获分组匹配的字符,因此匹配文本为undefined
1 | > /^(?!([-a-zA-Z0-9.]{0,255}))/.exec('_ example_.com'); |
匹配模式
匹配模式,指的是匹配时遵循的规则,不同的模式会影响正则表达式的识别以及正则表达式中字符的匹配范围
格式
/regexp/[mode] 或 new RegExp('regexp', 'mode')
- mode 模式修饰符
JavaScript 修饰符的作用范围是整个正则表达式
JavaScript 可以混用多个模式,把模式修饰符连续列出来即可
不区分大小写模式
不区分同一个字母的大小写
修饰符 i -- case Insensitive
单行模式
也有叫 DOTALL 点号通配模式
将所有(多行)文本视作一行,换行符只是这一行中的普通字符
单行模式影响点号 . 的匹配范围:在默认模式下,点号.可以匹配除换行符之外的任何字符,在单行模式下,点号.可以匹配包括换行符在内的任何字符
默认模式需要使用
[\s\S]匹配任意字符
修饰符 s -- Single line
多行模式
多行模式影响 ^ 和$ 的匹配范围
修饰符 m -- Multiline
全局模式
找到所有匹配项,直到字符串结尾
修饰符 g -- Global
Unicode 模式
修饰符 u -- Unicode
指定码值的形式为\u{xxxx}
1 | > /\u{4e25}/u.exec('严'); |
中文字符大多位于 CJK区间
4E00-9FFF
2
[ '严', index: 0, input: '严', groups: undefined ]
定点模式
修饰符 y -- Sticky Mode
提前指定正则表达式开始匹配的位置
- 一旦指定的位置匹配失败,则整个正则表达式匹配失败,不更换其他位置重新尝试,重置
lastIndex - 匹配成功后,更新
lastIndex的位置
1 | > a=/34/uy; |
转义
字符串转义
我们平常看到和书写的都是字符串文字(String Literal),是字符串在代码中的表现形式,当代码执行时进行字符串转义才能识别为字符串。但是表述的时候一般将字符串文字直接称为字符串
| 字符串文字 | 字符串 | 描述 |
|---|---|---|
| \n | NL | 换行符 |
| \t | Tab | 制表符 |
| \\ | \ | 反斜杠字符 |
例如字符串文字 ‘\n’ ,包含 \ 和 n 两个字符,是字符串
换行符在代码中的表现形式,代码执行时进行字符串转义,识别为换行反斜杠
\具有转义功能,在代码执行时,可以将普通字符识别为特殊字符,也可以将特殊字符识别为普通字符例如普通字符
n,与反斜杠一起\n转义识别为特殊字符NL。特殊字符\,与反斜杠一起\\转义识别为普通字符\1
2
3
4
5
6
7
8> console.log('\\');
\ // 转义为普通字符 \
undefined
> console.log('\n');
// 转义为换行符,在第一行末尾输出换行符,两行
undefined
>处理字符串时,反斜杠
\和其之后的字符被认为是转义序列(Escape Sequence)\n\t都是合法的转义序列
正则转义
我们平常看到和书写的都是正则表达式文字(Regular Expression Literal),是正则表达式在代码中的表现形式,当代码执行时进行正则转义才能识别为正则表达式。但是表述的时候一般将正则表达式文字直接称为正则表达式
- 例如正则表达式文字
\d,包含 \ 和 d 两个字符,是正则表达式字符组在代码中的表现形式,代码执行时进行正则转义,被正则引擎识别为字符组去匹配
字符串形式
以字符串形式提供正则表达式,需要经过字符串转义和正则转义,才能被正则引擎识别为正则表达式

| 字符串文字 | 字符串/正则文字 | 正则表达式 | 描述 |
|---|---|---|---|
| ‘\\n’ | \n | NL | 换行符 |
| ‘\\t’ | \t | Tab | 制表符 |
| ‘\\\\‘ | \\ | \ | 反斜杠 |
1 | > new RegExp('\\\\','g').exec('\\') |
- 字符串文字 ‘\\\\‘ 经过字符串转义和正则转义,的到正则表达式
\ - 字符串文字 ‘\\‘ 经过字符串转义,得到字符串 ‘\‘
不可见字符
可以只进行字符串转义,一旦识别为不可见字符,可直接传递给正则表达式,不需要经过正则转义
| 字符串文字 | 字符串/正则文字 | 正则表达式 | 描述 |
|---|---|---|---|
| \n | NL | NL | 换行符 |
| \t | Tab | Tab | 制表符 |
| \b | BS | BS | 退格符 |
| \\b | \b | \B | 单词边界 |
上表中的不可见字符串文字,在经过字符串转义时,已经被识别为不可见字符串,传递给正则表达式时已经包含在字符串中了,直接生效
1
2
3
4
5
6
7
8
9aa = new RegExp('\n','g')
/\n/g
> aa.test('\n')
true
>
> bb = new RegExp('\\n','g')
/\n/g
> bb.test('\n')
true正则表达式
\b,在字符串文字中需要写成 ‘\\b’,否则会识别为退格符1
2
3
4> new RegExp('\bcat\b').exec('cat');
null
> new RegExp('\\bcat\\b').exec('cat');
[ 'cat', index: 0, input: 'cat', groups: undefined ]
正则文字形式
以正则文字/RegExp/形式提供正则表达式,只需要考虑正则转义,在字符前面加反斜杠 \ 或特殊写法
特殊写法
字符组
普通字符组中转义横线-,将横线紧跟在[之后
[-09]表示三个字符-09
[-a-z]表示字符-和范围a-z
排除字符组中转义横线-,将横线紧跟在^之后
[^-09]表示-09之外的字符
[^0-9]表示范围0-9之外的字符
排除字符组中转义脱字符^,不要将^紧跟在[之后
[0^12]表示4个普通字符0^12
反斜杠\
正则表达式的两种表现形式
普通字符转义为元字符
- 普通字符 d 转义 元字符 \d 表示匹配数字字符
元字符转义为普通字符
- 元字符 . 转义 普通字符 \. 表示普通字符点号 .
- 字符组内部的闭方括号
]需要转义\],否则会提前匹配开方括号 - 括号内部的闭括号
)需要转义\),否则会提前匹配开括号
特殊字符转义为普通字符
反斜杠需要转义为
\\1
2> /\\/.test('\\')
true
特殊情况
字符组本身,只需要转义开方括号
[即可\[01]表示匹配字符串[01]字符组内需要转义的字符有
]-^\,其他元字符在字符组内都视作普通字符1
2
3
4> /[*]/.test('*')
true
> /[()]/.test('()')
true通用形式量词本身,只需要转义开大括号
{即可\{m,n}表示匹配字符串{m,n}忽略优先量词本身,需要将两个量词都转义
\*\?表示匹配字符串*?括号
()及多选结构中的竖线|本身,需要将三个元字符都转义1
2
3
4
5
6
7
8
9
10> /^\(a|b\)$/.exec("(a|b)")
[ '(a', index: 0, input: '(a|b)', groups: undefined ]
> /^\(a|b\)$/.exec("(c|b)")
[ 'b)', index: 3, input: '(c|b)', groups: undefined ]
# 以上情况未转义竖线,正则表达式匹配字符串 "(a" 或 "b)"
> /^\(a\|b\)$/.exec("(a|b)") # 转义竖线后,正则表达式匹配字符串 "(a|b)"
[ '(a|b)', index: 0, input: '(a|b)', groups: undefined ]
表达式优先级
正则表达式由元字符组合而成,有4种组合关系,正则引擎在处理组合时有优先级之分,优先级高的优先处理
| 优先级 | 组合 | 示例 |
|---|---|---|
| 1(高) | 括号 | (abc) |
| 2 | 量词 | a*b |
| 3 | 普通拼接 | abc |
| 4(低) | 多选结构 | ab|cd |
多选结构
多选结构可以有括号,也可以没括号。因为多选结构的优先级最低,需要注意正则表达式的处理顺序,建议用括号明确多选结构的范围,如果不需要匹配则用非捕获括号
例如表达式
^ab|cd$,多选结构|优先级低于普通组合^abcd$,因此等价于(^ab|cd$)而非^(ab|cd)$。
匹配原理
有穷状态机
具备有限个状态,可以根据不同的条件在状态之间转移的程序叫有穷自动机。
必须满足4个条件
- 具有有限个状态
- 具有一套状态转移函数
- 有一起始状态
- 有一个或多个最终状态
正则表达式使用的理论模型就是有穷状态机,具体实现称为正则引擎(Regex Engine)
DFA
Definite Finite Automata 确定型有穷自动机
在某个时刻,它所处的状态是确定的
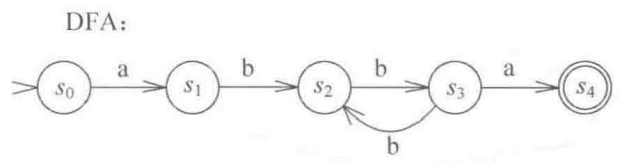
NFA
Non-definite Finite Automata 非确定型有穷自动机
在某个时刻,它所处的状态是不确定的
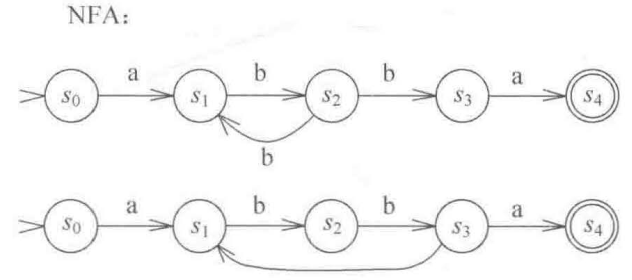
DFA vs NFA
同一个正则表达式构建的 DFA 和 NFA 是等价的可以互相转换
构建时间
NFA比DFA的短
状态保存
DFA状态转移是确定的,不会两次测试同一个字符,不需要保存匹配状态
NFA状态转移是不确定的,会多次测试同一个字符,需要保存匹配状态
功能
NFA因为保存了匹配状态,可以提供捕获分组、反向引用、环视、忽略优先量词等功能
回溯
backtracking
NFA引擎在匹配时,记录所有可能的状态,选择某个状态尝试,尝试匹配失败则退回去,选择最近保存的其他状态进行尝试,这种尝试失败-重新选择的过程,就是回溯
匹配过程
生成自动机
即编译正则表达式对象
同一个正则表达式可以对应多台不同的有穷自动机
匹配字符串
根据输入的字符串,在状态之间转移
从字符串的起始位置开始匹配,对某个字符,如果有多个可能的状态,NFA引擎会保存这些状态(匹配了哪些字符,进行到字符串中的哪个位置,正则表达式中的哪个位置等),然后选择一个状态进行尝试,如果后续字符无法匹配后续正则子表达式,即无法到达最终状态,则匹配失败,回溯,重复这个过程,直到最终状态。此时可以说——在字符串的当前位置,整个正则表达式匹配成功。如果在字符串的当前位置,所有可能的状态都尝试失败,如果该位置是字符串的末尾,则整个正则表达式匹配失败;否则,把当前位置向前移动一个字符,开始新一轮的匹配
开始匹配的位置一般是字符串的起始字符或由引擎的
lastIndex属性指定。lastIndex 仅作为正则表达式带有
/g标识时,exec 和 test 方法的起始位置每次执行正则表达式只能捕获一个符合规则的内容
拒绝服务攻击
Regular Expression Denial of Service
造成大量回溯的表达式,消耗计算机资源
当需要根据用户输入的字符串构建正则表达式进行查找时,需要消除用户输入字符串中元字符的特殊含义,否则构建的正则表达式匹配过程会消耗非常多的资源,可能把服务器拖垮
例如,根据用户输入的字符串 ‘cat’ 查找文件中包含 ‘cat’ 的行,构建的正则表达式就是 /^.*cat.*$/m,如果用户输入的是 ‘c(a*a*)a*t’,构建的正则表达式 /^.*c(a\*a\*)a*t.*$/ 在匹配过程中涉及到回溯呈指数级增加,非常消耗资源
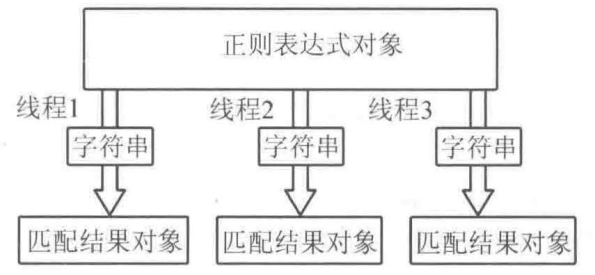
线程安全
正则表达式操作一般会生成两个对象
Java .NET Python 中会生成两个对象
JavaScript 中只有一个对象,既是正则表达式对象又保存了匹配状态信息,不能用于多线程
正则表达式对象
对应正则表达式
没有状态,线程安全,可以由多个线程共享
匹配结果对象
- 保存匹配结果
- 需要维护自身状态,包括匹配成功与否、匹配结束的偏移值等,线程不安全,不能由多个线程共享
因此,多个线程共享同一个正则表达式对象(节省开销),操作不同的字符串时,为每个线程生成独立的匹配结果对象
编码环境
编码环境指代码和处理的文本采用的编码
尽量使用Unicode编码环境,例如指定代码和文本采用 UTF-8 编码
编码环境会影响元字符的匹配范围
JavaScript
\d和\w采用ASCII编码,\s采用 Unicode 编码